背景
气象分析中,常会涉及基于多因子的建模的问题,例如对模式输出结果的订正、目前使用较多的风速、降水、污染浓度的预测等等。而在台风强度预报的建模中,目前最常使用的是多元回归、偏最小二乘法等传统统计方法.
传统统计方法对于描述线性关系有较好的性能,但对于非线性的过程通常难以表征,而机器学习的方法无论是线性还是非线性的过程,都能有较好的表现。并且有一些研究通过对比同样数据量下的一些机器学习和传统回归方法的预测精度,机器学习表现出较大的优势。因此,在气象分析中,机器学习方法具有较大的潜力。
本文简单介绍了如何使用scikit-learn的基本回归方法(线性、决策树、SVM、KNN)和集成方法(随机森林、Adaboost和GBRT)进行多因子建模,并根据建模结果选择适宜的模型。
数据和导入
使用到的数据为台风环境场因子、台风持续性因子和台风强度,其中自变量为11个因子,因变量为台风强度。由于环境场因子在实际预报中使用到的是未来时刻的模式输出结果,因此,在本模型中只需对台风强度进行预测,而无需对因子进行预测。
导入包括因变量和11个自变量的数据,将前2000行作为训练集svm 风速预测代码,后面的作为测试集。
#导入使用到的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import DecisionTreeRegressor
from sklearn import linear_model
from sklearn import tree
from sklearn import neighbors
from sklearn import svm
from sklearn import ensemble
#数据导入
data=pd.read_csv('example.csv')
y_train = data.iloc[0:2000,0]
y_test = data.iloc[2001:,0]
x_train = data.iloc[0:2000,1:]
x_test = data.iloc[2001:,1:]
y_train = np.array(y_train)
y_test = np.array(y_test)
x_train = np.array(x_train)
x_test = np.array(x_test)
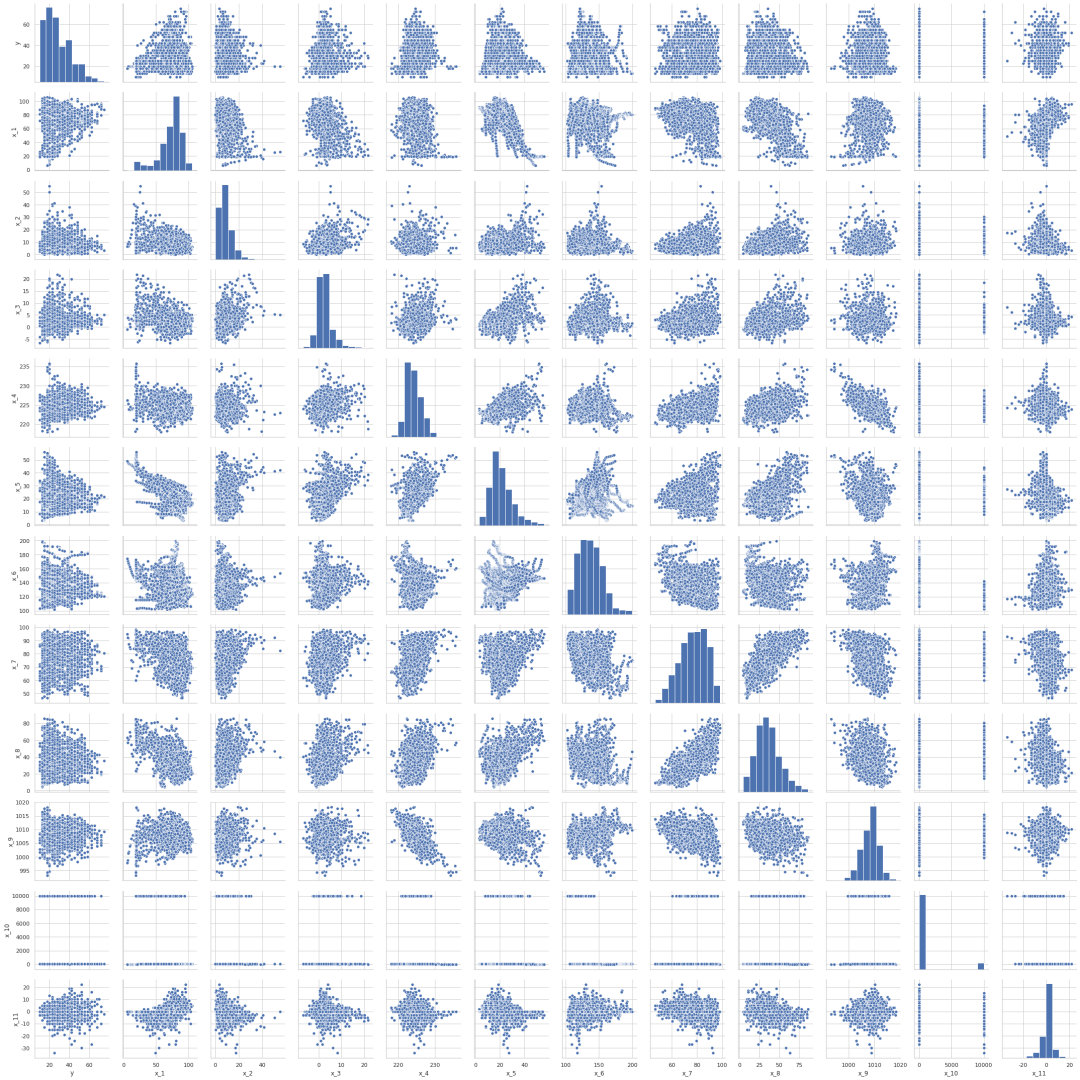
数据可视化散点图矩阵
pairplot出各因子本身数值的矩形分布以及因子和因子两两之间的散点分布
更精细的修改图片形式的可参考教程[]
sns.set(style='whitegrid', context='notebook') #style控制默认样式,context控制着默认的画幅大小
sns.pairplot(data, size=2.5)
plt.tight_layout()
plt.show()
相关系数热图
计算因子之间的皮尔逊相关系系数
cm = np.corrcoef(data.values.T) #corrcoef方法按行计算皮尔逊相关系数,cm是对称矩阵
#使用np.corrcoef(a)可计算行与行之间的相关系数,np.corrcoef(a,rowvar=0)用于计算各列之间的相关系数,输出为相关系数矩阵。
sns.set(font_scale=0.5) #font_scale设置字体大小
hm = sns.heatmap(cm,cbar=True,annot=True,square=True,fmt='.2f',annot_kws={'size': 5})
plt.show()
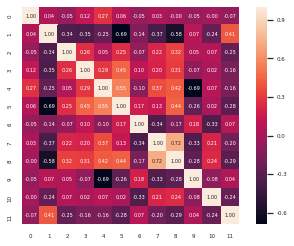
从第一行可以看出各因子和因变量之间的相关性。
sns.reset_orig() #将参数还原为seaborn作图前的原始值
%matplotlib inline
scikit-learn简单介绍
scikit-learn非常简单,只需实例化一个算法对象,然后调用fit()函数就可以了,fit之后,就可以使用predict()函数来预测了svm 风速预测代码,然后可以使用score()函数来评估预测值和真实值的差异,函数返回一个得分。
例如调用决策树的方法如下
clf = DecisionTreeRegressor()
clf.fit(x_train,y_train)
result = clf.predict(x_test)
clf.score(x_test,y_test)
-0.31049453842336394
根据预测值和真值画图
plt.figure()
plt.plot(np.arange(len(result)), y_test,'go-',label='true value')
plt.plot(np.arange(len(result)),result,'ro-',label='predict value')
plt.legend()
plt.show()
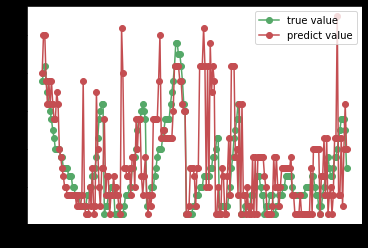
在趋势和极值点附近的预报性能比较一般
试验各种不同的回归方法并计算得分
def try_different_method(clf):
clf.fit(x_train,y_train)
score = clf.score(x_test, y_test)
result = clf.predict(x_test)
plt.figure()
plt.plot(np.arange(len(result)), y_test,'go-',label='true value')
plt.plot(np.arange(len(result)),result,'ro-',label='predict value')
plt.title('score: %f'%score)
plt.legend()
plt.show()
线性回归
linear_reg = linear_model.LinearRegression()
try_different_method(linear_reg)
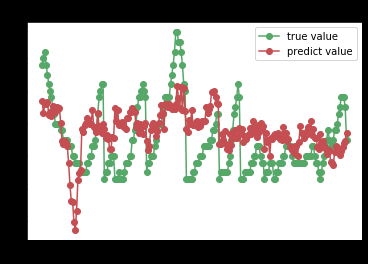
决策树回归
tree_reg = tree.DecisionTreeRegressor()
try_different_method(tree_reg)
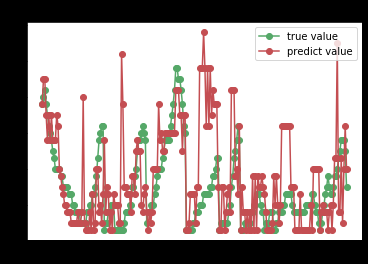
SVM回归
svr = svm.SVR()
try_different_method(svr)
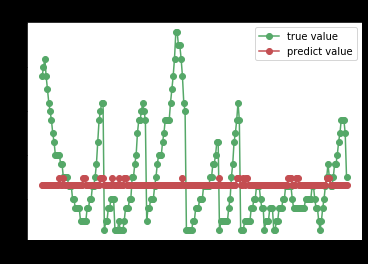
KNN
knn = neighbors.KNeighborsRegressor()
try_different_method(knn)
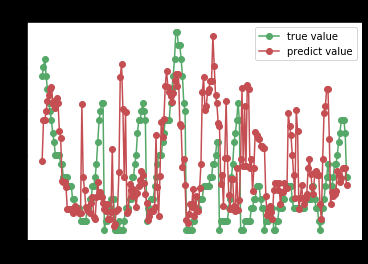
随机森林
rf =ensemble.RandomForestRegressor(n_estimators=20)#这里使用20个决策树
try_different_method(rf)
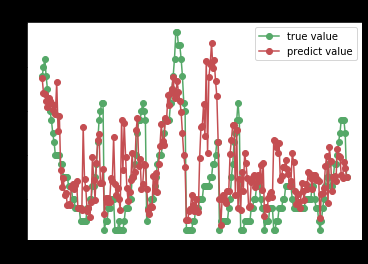
Adaboost
ada = ensemble.AdaBoostRegressor(n_estimators=50)
try_different_method(ada)

GBRT
gbrt = ensemble.GradientBoostingRegressor(n_estimators=100)
try_different_method(gbrt)
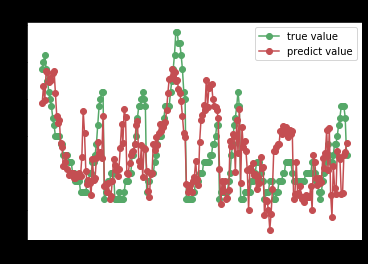
从上面的评分来看,拟合效果最好的是决策树,可以继续在决策树中寻找更好的方法去解决这个回归的问题。
学习这些代码的目标,主要在于在数据已经确定的情况下,快速的寻找最适合的模型做预测。如果涉及到时序预测的话,时效小的训练集数据量大,时序大的训练集数据量小,算法是否能在数据量差异大的情况下,具有比较稳定的表现,也是在建模预测中需要考虑的点。
视频课程推荐
1
气候水文耦合WRF-Hydro模式实践技术应用课程
2
空气质量预报模式系统(wrf-cmaq)改进与污染源排放清单建立实践技术精品课程
3
高分辨率区域气候模式(WRF)在地学、生态环境、水文及能源领域中的实践技术应用精品课程
4
区域气象-大气化学在线耦合模式(WRF/Chem)在大气环境中的应用课程
5
基于GIS探究环境和生态因子对水体、土壤、大气污染物的影响课程
6
基于SMOKE模型的多模式排放清单处理技术推广课程
7
NCL数据分析与处理实践技术应用视频课程
8
9
视频教程+课件资料及数据代码+导师随行辅导
联系课程专员,最高享受7.5折优惠
扫码了解课程详情
添加小编微信,海量数据、视频教程免费获取

END
海量数据免费获取
+
Ai尚研修海量资源(数据、课件、书籍、视频教程)一键免费领取
(点击数据标题,直接进入)

发表评论